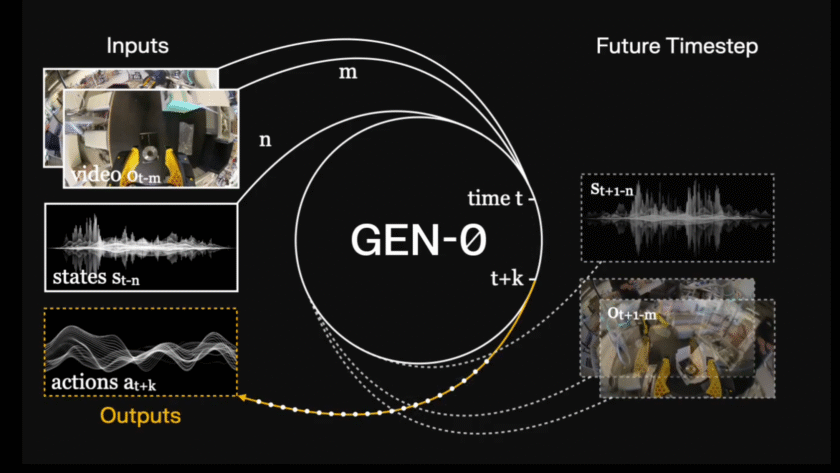
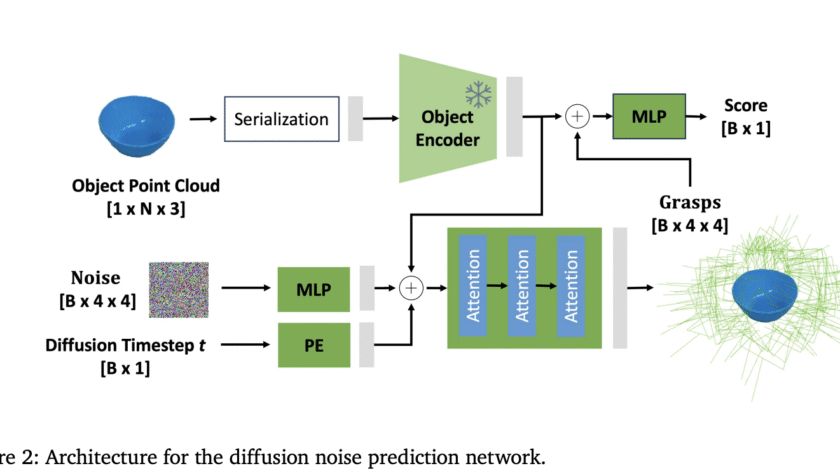
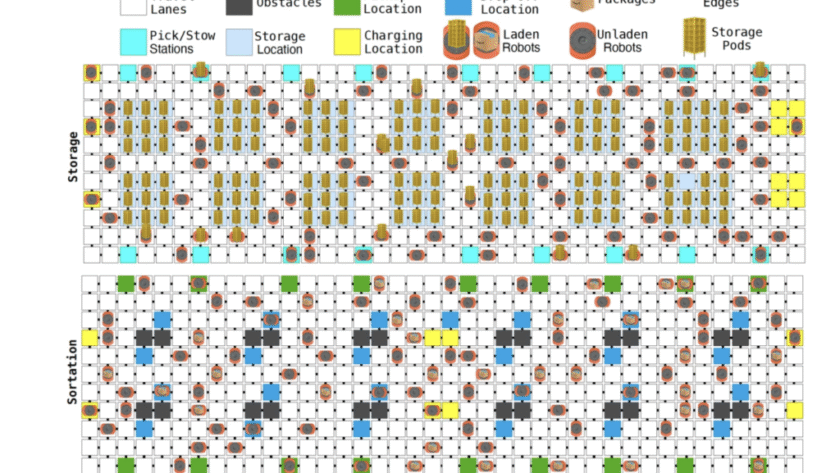
How do you build a single model that can learn physical skills from chaotic real world robot data without relying on simulation? Generalist AI has unveiled GEN-θ, a family of embodied foundation models trained directly on high fidelity raw physical interaction data instead of internet video or simulation. The system is built to establish scaling…